
起原:中信建投证券研究
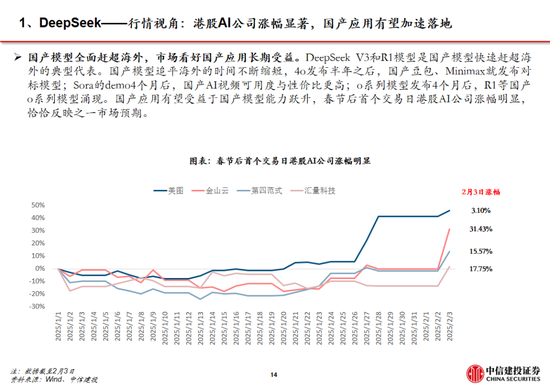
中国DeepSeek爆火全球,为AI行业的发展注入了簇新的活力,全面引颈AI海浪。
近期DeepSeek多款模子上线并完全开源,其中R1在推理任务上基本罢了于o1特殊的性能,Janus-Pro 在多模态清楚和生成方面阐扬较好。受春节信息传播下千里促进,DeepSeek出圈并成为全球增速最快的 AI 原生应用,日活跃用户数在2月1日突破3000万大关。此外,DeepSeek通过算法迭代、架构升级,使通用及推理模子成本相较于OpenAI同类模子着落至数十分之一以下。
中信建投证券筹算机、东说念主工智能、通讯、传媒、策略研究团队推出【DeepSeek产业链投资机遇】:
01 DeepSeek中枢十问十答
DeepSeek-R1模子发布,具有高性能、低算力需求的秉性,带动小模子推理能力的进步,激勉全球开发者及用户柔和。R1手脚开源模子性能接近头部闭源模子o1,一定程度上已经反应了AI平权,同期纯强化学习对推理能力的进步带来RL范式泛化可能,瞻望后续基模的持续迭代,有望推动AI全产业链持续保持高景气和高柔和度,柔和算力、应用、端侧、数据等中枢投资契机。
DeepSeek模子密集更新,高性能+低成本促进用户数高增
近期DeepSeek多款模子上线并完全开源,其中R1在推理任务上基本罢了于o1特殊的性能,Janus-Pro 在多模态清楚和生成方面阐扬较好。受春节信息传播下千里促进,DeepSeek出圈并成为全球增速最快的 AI 原生应用,第18天达到1500万日活。此外,DeepSeek通过算法迭代、架构升级,使通用及推理模子成本相较于OpenAI同类模子着落至数十分之一以下。
时间不时调动,大模子Scaling Law仍灵验
DeepSeek通过多头潜在防卫力、MoE、多token预测等架构和基础设施创新罢了了高效测验,并在R1-Zero模子考证了纯强化学习对推理能力的进步。尽管Pre-Training Scaling面对时间、算力、数据的制约,但强化学习带来了限度化扩展新所在,瞻望各厂商将陆续跟进,持续优化模子架构。
DeepSeek-R1促进AI平权,产业链享受发展红利
R1手脚开源模子性能接近头部闭源模子o1,一定程度上已经反应了AI平权。同期,R1使小模子具备推理能力成为可能,更低的成本将更成心于开发者探索AI的现实落地。
一、DeepSeek模子密集更新,高性能+低成本促进用户数高增
1.1 第一问:DeepSeek的用户量趋势?
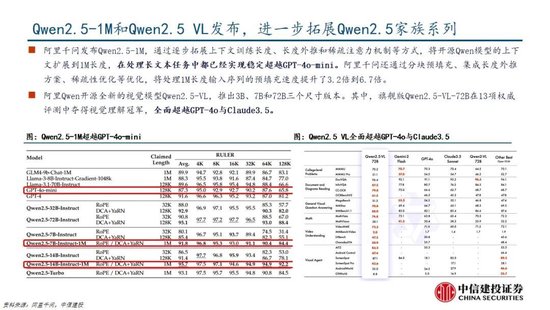
DeepSeek坚强开源蹊径,密集更新MoE、推理、多模态模子。近期,DeepSeek连气儿发布并开源多个大模子,其低成本、高性能的秉性连忙激勉全球用户的柔和。其中,2024年12月26日发布的DeepSeek-V3为671B参数的自研 MoE 模子,运行时仅需激活37B,在 14.8T token 的数据上进行了预测验;2025年1月20日发布的DeepSeek-R1为660B的高性能推理模子,对用户开放念念维链输出,允许用户通过蒸馏时间借助 R1 测验其他模子;2025年1月27日,DeepSeek在Hugging Face平台上传了视觉模子 Janus-Pro和多模态清楚模子JanusFlow -1.3B,进一步在图像范畴发力。
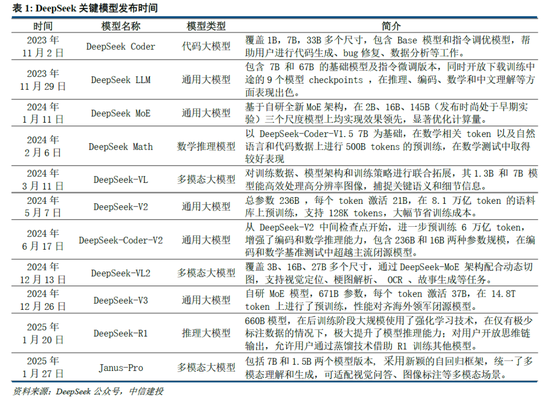
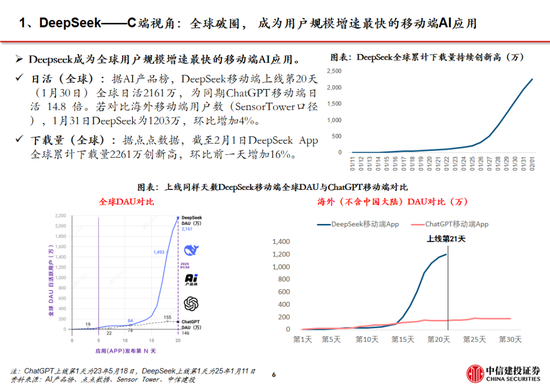
DeepSeek Web端与APP端访谒量持续增长,春节信息传播下千里加快居品柔和度裂变。Web端,2024年10月至2024年12月DeepSeek访谒量分别为245/422/1101万,其中11月和12月分别同比增长72.24%/160.90%,12月受全新开源模子V3促进访谒量大幅增长;APP端,DeepSeek 2025年1月10日(官方公众号1月15日庄重发文)在iOS/Android上线官方APP,此后受益于1月20日发布R1模子的高性能、低成本,叠加春节期间信息传播下千里,居品柔和度呈裂变式增长。具体而言,DeepSeek APP安卓/iOS端国区单日下载量均于1月26日前后迎来陡增,至1月29日单日下载量分别达到784.15/29.92万;同期,DeepSeek 安卓端在华为应用商店下载名次中位列第四,iOS端则霸榜全球173个地区中160/162/171个总榜(免费)/应用(免费)/遵循(免费)第一;此外,从居品发布日起日活用户看,DeepSeek第5天突出 ChatGPT,第15天以259万日活达到 ChatGPT 的2倍,亦为全球增速最快的 AI 原生应用,第18天达到1500万日活,而ChatGPT上线第244天才达到1500万DAU。
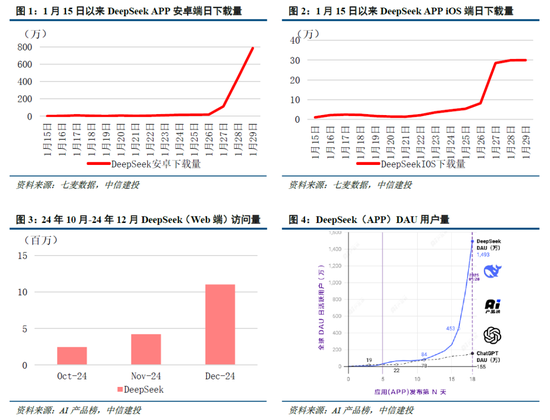
咱们觉得,DeepSeek用户数将持续高速增长。一方面DeepSeek手脚开源蹊径的坚强践行者,有望受到全球开发者的高度柔和;另一方面受益于春节期间信息传播下千里,DeepSeek的国内渗入率将持续进步。
1.2 第二问:R1和Janus-pro模子的性能如何?
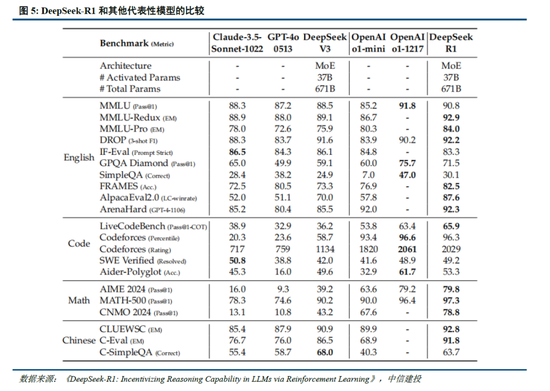
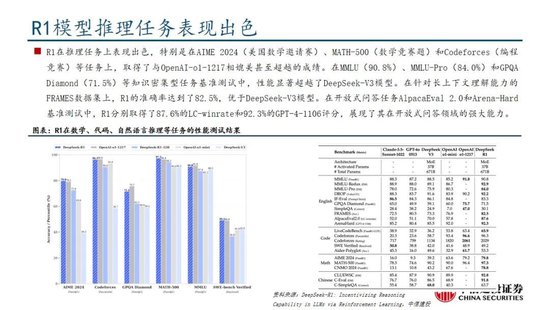
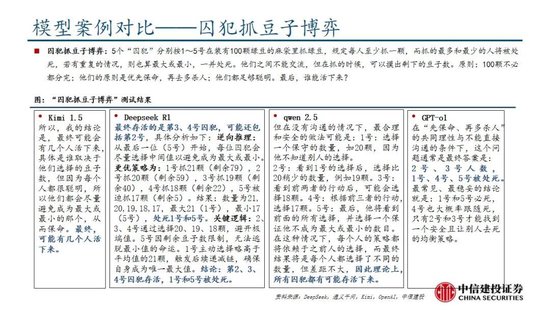
DeepSeek-R1 在推理任务上基本罢了与 OpenAI-o1特殊的性能,较o3模子仍有差距。DeepSeek在R1模子的测试过程中,登科英文、中语、数学、代码等基准测试,与Claude-3.5、GPT-4o、DeepSeek-V3、OpenAI o1、OpenAI o1-mini等模子进行比较:
熟谙为导向的学问任务:在以MMLU(R1 90.8分;V3 88.5分;o1 91.8分)和GPQA Diamond(R1 71.5分;V3 59.1分;o1 75.7分;o3 87.7分)为代表的学问基准上,R1比拟V3阐扬出更优厚的性能,主因大限度强化学习(RL)促进STEM关联问题上准确性权贵进步;在依赖长高下文的FRAMES(R1 82.5分;V3 73.7分)基准,R1相同展示了强壮的文档分析能力。
中英文搜索和数据分析任务:在英文事实基准测试SimpleQA(R1 30.1分;V3 24.9分;o1 47.0分)上,R1优于V3,展现了模子基于事实的查询能力;而在中语事实基准测试C-SimpleQA(R1 63.7分;V3 68.0分)上,R1阐扬不如V3,主要系安全强化学习后模子倾向于隔绝修起某些查询。要是莫得安全RL, R1的准确率不错突出70%。此外,R1模子在IF-Eval(R1 83.3分;V3 86.1分)、AlpacaEval2.0(R1 87.6分;V3 70.0分)和ArenaHard(R1 92.3分;V3 85.5分)等基准测试中相同阐扬较好,展现了模子在遵命局势指示、写稿任务和开放域问答上的能力。
数学任务:在数学任务上, R1 阐扬出与 o1特殊的性能,优于其他非推理模子,杰出了推理模子在数学测试中的主导地位。举例在AIME 2024基准上,R1/V3/o1/o3分别得分79.8/39.2/79.2/96.7分;在Math-500基准上,R1/V3/o1分别得分97.3/90.2/96.4分。
编码任务:推理模子在数学测试中相同阐扬更佳,举例在Codeforces基准上,R1/V3/o1/o3分别得分2029/1134/2061/2727分,分别突出96.3%/58.7%/96.6%/99.9%的东说念主类参赛者;在SWE-bench Verified基准上,R1/V3/o1/o3分别得分49.2/42.0/48.9/71.7分。
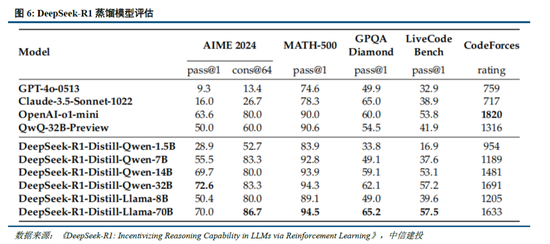
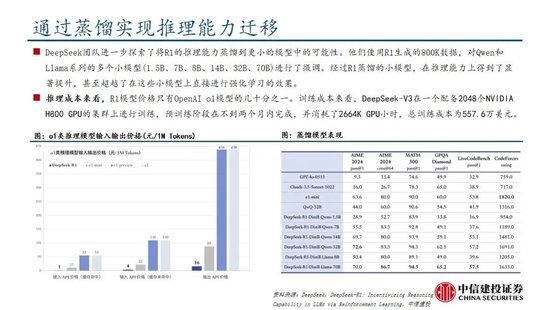
蒸馏时间能权贵进步小模子推理能力。通过向更高效的小模子蒸馏DeepSeek-R1的输出,粗鲁权贵进步小模子推理能力。举例,向Qwen2.5-Math-7B蒸馏R1模子得到的DeepSeek-R1-Distill-Qwen-7B(简称R1-7B,下同),全面超越非推理模子如GPT-4o;向Qwen2.5-14B蒸馏得到R1-14B在通盘评估方针上均突出了QwQ-32B-Preview;而向Qwen2.5-32B和Llama-3.3-70B-Instruct蒸馏得到的R1-32B和R1-70B在大多数基准测试中权贵超越了o1-mini。
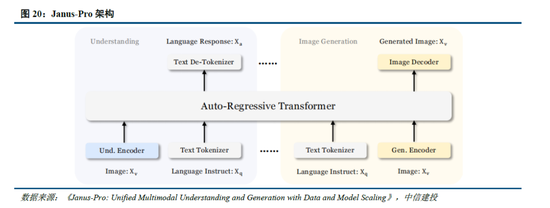
Janus-Pro 在多模态清楚和生成方面优于消释模子和单一功能模子。Janus-pro主要延续Janus通过解耦多模态清楚和生成的研究念念路,通过优化测验策略、扩展测验数据和模子限度等方面提高模子性能:
多模态清楚:在Janus测试过程中登科POPE、MME-P、MMB、SEED、MMMU、MM-Vet等平庸招供的图像视觉谈话基准测试,同期包括了一种用于真实天下视觉推理和组合式问答的新数据集GQA。与其他前沿图像清楚生成消释模子和仅用于清楚的模子比拟,Janus-Pro 取得了总体最好的收尾,举例Janus-Pro-7B在多模态清楚基准MMBench上得分79.2,超越了包括Janus(69.4)、TokenFlow(68.9)和MetaMorph(75.2)等,主因其将多模态清楚和生成的视觉编码解耦,缓解了这两个任务之间的冲突。此外,Janus-Pro与限度更大的模子比拟仍具竞争力,举例Janus-Pro-7B在除GQA外的其他基准测试上的阐扬都优于 TokenFlow-XL(13B)。
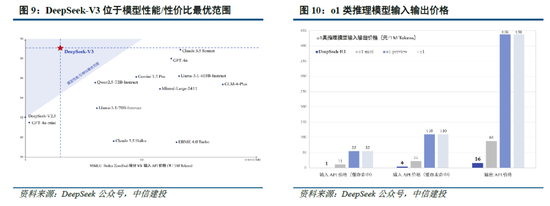
文本-图像生成:为评估Janus视觉生成能力,DeepSeek采取 GenEval(文本到图像构图能力基准测试)和 DPG-Bench(密集教导图基准测试)两个器具进行测试。Janus-Pro-7B 在 GenEval 上的总体准确率达到 80%,突出了通盘其他消释模子或仅用于生成的模子,包括Transfusion(63%)、SD3-Medium(74%)和 DALL-E 3(67%),反应Janus-Pro具有更好的指示作陪能力。同期,Janus-Pro 在 DPG-Bench 上的得分为 84.19,突出了通盘其他方法,标明 Janus-Pro 在遵命用于文本到图像生成的密集指示方面阐扬出色。
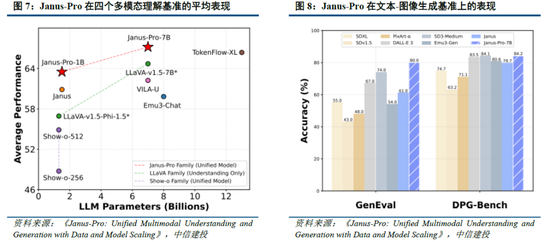
咱们觉得,DeepSeek-R1性能已基本达到OpenAI-o1水平,较o3模子基准测试阐扬仍有不小差距,跟着DeepSeek在MoE架构、强化学习等时间上进一步迭代,推理模子性能阐扬存望持续增长;Janus-Pro在多模态清楚和生成方面则相对阐扬较好,一定程度考证了图像清楚和生成解耦念念路的可行性。
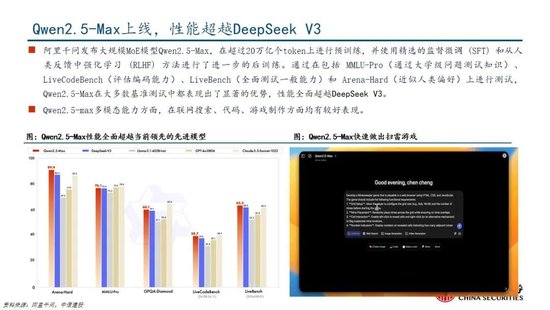
1.3 第三问:如何看待DeepSeek-V3模子的测验成本?
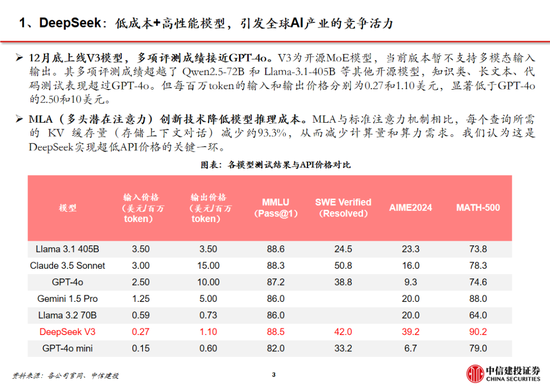
DeepSeek通用及推理模子成本相较于OpenAI同类模子着落至数十分之一以下:
通用模子方面,2024年12月26日DeepSeek-V3更新上线,模子API干事订价调换为每百万输入tokens 0.5元(缓存射中)/ 2元(缓存未射中),每百万输出tokens 8元。此外,V3模子建立长达45天的优惠价钱体验期:2025年2月8日前,V3的API干事价钱仍保持每百万输入tokens 0.1元(缓存射中)/ 1元(缓存未射中),每百万输出tokens 2元。与此同期,OpenAI GPT-4o的API干事订价为每百万输入tokens 1.25好意思元(缓存射中)/ 2.5好意思元(缓存未射中),每百万输出tokens 10好意思元。
推理模子方面,DeepSeek-R1 API 干事订价为每百万输入 tokens 1元(缓存射中)/ 4元(缓存未射中),每百万输出 tokens 16元。而OpenAI o1的API 干事订价为每百万输入 tokens 7.5好意思元(缓存射中)/ 15好意思元(缓存未射中),每百万输出 tokens 60好意思元。
需要防卫的是,不同模子token切分方法可能不同,闲居1 token可对应1-2个中语汉字,或对应3-4个英翰墨符,或0.75个英文单词。
DeepSeek-V3(R1的基础模子)总测验成本仅为 557.6 万好意思元,但不包括架构、算法等成本。以H800算力筹算,DeepSeek-V3预测验阶段在不到两个月的时辰内完成,耗尽266.4万个GPU小时,加上高下文长度扩展所需的11.9万个GPU小时和后测验阶段的0.5万个GPU小时,DeepSeek-V3的完竣测验仅需 278.8 万个 GPU 小时;假设 H800 GPU 的租用价钱为每 GPU 小时 2 好意思元,咱们的总测验成本仅为 557.6 万好意思元。需要防卫的是,上述成本仅包括 DeepSeek-V3 的庄重测验成本,不包括与架构、算法或数据的前期研究及消融实验关联的成本。

证据咱们测算,GPT-4需要2.5万张A100测验95天(5700万A100 GPU小时),OpenAI o1需要用3.2万张H100测验90天(6912万H100 SXM GPU小时):1)GPT-4由16个111B的MoE模子组成,其中两个用于上前传播,另有55B被用作念防卫力机制的分享,则GPT-4的激活参数目约为280B,咱们假设o1模子激活参数目是GPT-4的两倍,达到560B;2)GPT-4的预测验数据集token量为13B,咱们假设o1模子接近其两倍,达到25B;3)GPT-4的测验时辰约为90-100天,咱们取中间值95天,并假设o1的测验周期为90天;4)GPT-4的GPU期骗率在32%到36%之间,咱们取中间值34%,并假设o1 GPU期骗率也为34%;5)证据OpenAI在Scaling Laws 论文中给出的造就公式筹算(C = rT ≈ 6*P*D,P为模子参数目,D为测验集token大小,r为测验集群硬件FLOPS总浑沌),则OpenAI o1预测验需要用3.2万张H100。
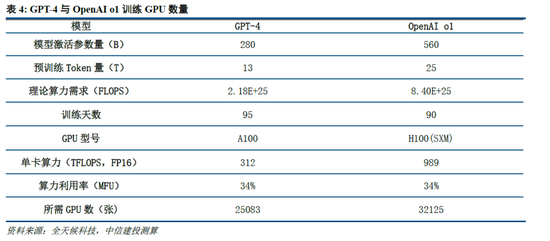
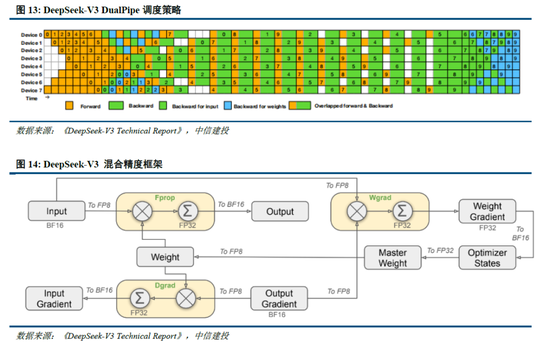
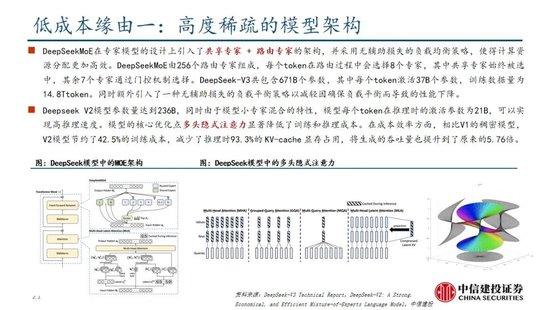
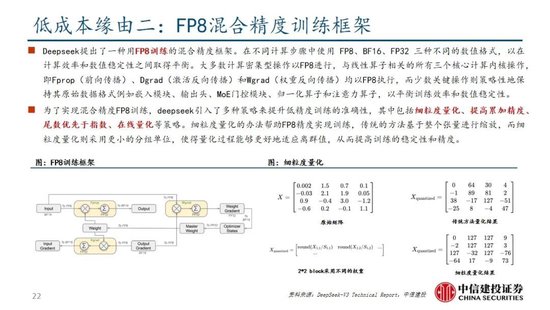
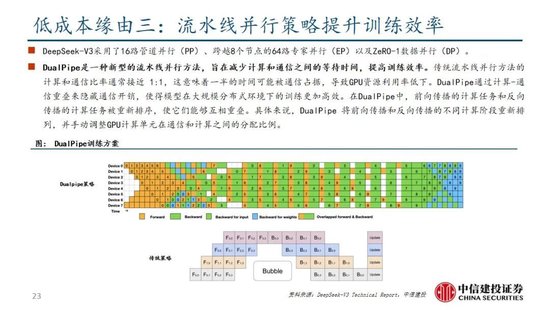
算法迭代、架构升级促进DeepSeek-V3模子测验成本阻挡,合乎产业趋势。相较于GPT-4和o1模子,DeepSeek-R1的基础模子DeepSeek-V3测验成本昭彰更低,结合V3时间证明和上述筹算过程,咱们觉得成本优化主要缘于:1)V3模子通过DeepSeekMoE架构(3.1中将进一步阐述),使用更细粒度内行模子,同期隔断部分分享内行,提高筹算资源期骗率,激活参数少(仅37B),算力消耗低;2)V3模子采取MLA算法(3.1中将进一步阐述),通过低秩贯串压缩防卫力键值,减少推理时的键值(KV)缓存,阻挡筹算量;3)Dual Pipe框架罢了高效活水线并行,或权贵提高GPU期骗率;4)DeepSeek建议了一种期骗FP8数据局势进行测验的细粒度羼杂精度框架,通过低精度测验优化测验遵循。
二、时间不时调动,大模子Scaling Law仍灵验
2.1 第四问:DeepSeek-V3/R1时间调动有哪些?
通过架构和基础设施创新,DeepSeek-V3罢了了高效测验,奠定R1模子优化基础。架构方面,DeepSeek-V3延续了V2模子的MLA和DeepSeek MoE架构,同期进一步草创了无补助圆寂的负载平衡策略,并设定了多token预测(MTP)测验主义以增强性能:
多头潜在防卫力(MLA):LLM的中枢理制是自防卫力(Self-Attention),其条目模子在生成每个token时辩论之前通盘词的联系,则假设文本长度n时总体复杂度为〖O(n〗^3)=O(Σn^2);往日的研究建议了KV Cache方法,期骗键值对(KV)存储已筹算的防卫力信息,此时总体复杂度阻挡为O(n^2);而MLA则进一步通过投影的时势,将token的相异信息通过投影矩阵存储,在险些不圆寂信息的情况下减少键值的缓存需求。
DeepSeekMoE:内行羼杂模子(MoE)是面前大模子时间中对前馈神经麇集(FNN)的一种替代决策。不同于FNN需要沿途权重参与筹算,MoE期骗门控机制判断输入数据需要由哪些内行模子参与处理。相较于主流MoE模子,DeepSeekMoE使用更细粒度的内行,并隔断一些模子手脚分享内行,进一步优化了激活参数。此外,为科罚内行负载不服衡导致的路由崩溃和筹算遵循阻挡,DeepSeek建议无补助圆寂负载平衡策略,为每个内行模子添加可动态调换的偏差项,确保测验过程中内行负载平衡、提高模子性能。
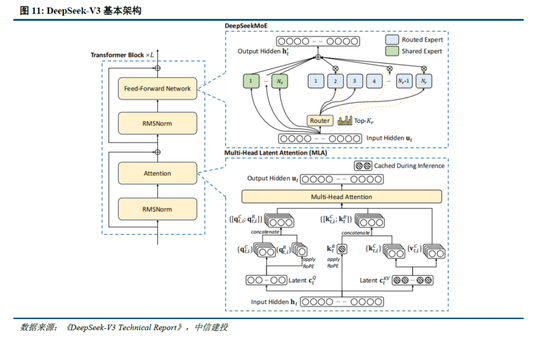
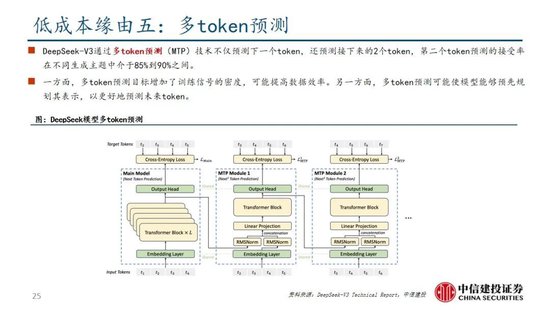
多token预测(MTP):主流大模子token-by-token生成序列,而每次token生成需要时常与访存交互,从而因为访存遵循形成测验或推理的瓶颈。MTP方法主要将单token的生成,调动成多token的生成,进步测验和推理的性能。DeepSeek主要对过往MTP算法进行了一定优化,规章预测额外token,并在每个预测深度保持完竣的因果链。
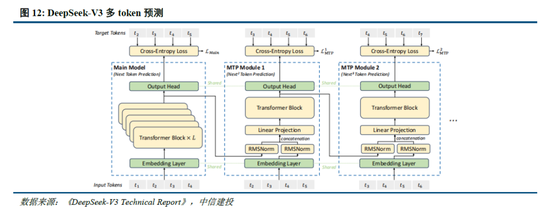
除了基础架构,DeepSeek还在基础设施方面进行了一定优化。举例遐想了一种创新的管说念并行算法 DualPipe,在每一双前向和后向块内重复筹算和通讯,提高通讯遵循、加快了模子测验;建议了一种用于 FP8 测验的羼杂精度框架,其中大多数筹算密集型操作在 FP8 精度下进行,而一些过错操作则政策性地保持在原始数据局势以平衡测验遵循和数值雄厚性;测验过程中,采取英伟达 PTX(并行线程实行)汇编级编程替代圭臬 CUDA 决策,罢了了硬件级深度优化,减少了筹算冗余,提高了推理速率。
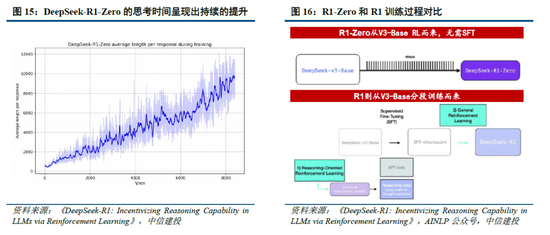
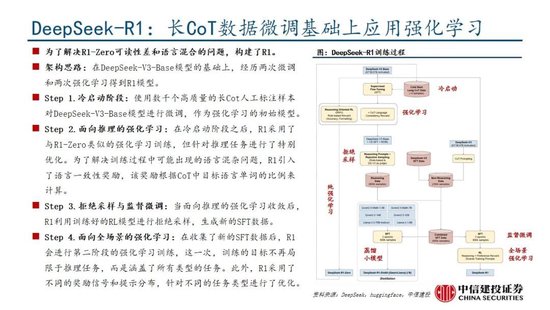
R1-Zero考证纯强化学习(RL)对推理能力的进步,R1则强调冷启动和多阶段测验的平衡。R1-Zero的稀奇之处在于,其无需任何监督微调数据即可获取强壮的推理能力,反应了模子仅通过强化学习就能灵验学习和泛化的能力。具体而言,R1-Zero模子在RL过程中延续了DeepSeek-V3组相对策略优化算法(GRPO),通过组内奖励对比优化策略,而不需要额外的判别器,最终罢了测验集上的平均响应长度持续进步,自然地学会了通过更多的念念考时辰来科罚推理任务;此外,R1-Zero测验过程自然地涌现出“念念考能力”,即模子自愿学会了重新评估其驱动修起,并为问题分派更多的念念考时辰,这种“反念念”的秉性粗鲁一定程度科罚大模子幻觉问题(大模子逐token输出,往日莫得机制去阅兵已经输出的失实,反而会连接用失实掩饰先前的问题,带来幻觉问题)。
尽管R1-Zero模子展现了强壮的推理能力,但仍面对可读性差媾和话羼杂等挑战,R1模子则通过冷启动和多阶段测验科罚了上述问题。R1相同从DeepSeek-V3-Base基础模子启程,经过数千条优质长链念念维(CoT)数据微调(SFT)手脚冷启动,使模子输出更合乎条目、可读性更强;此后,针对微调后的模子采取与R1-Zero换取的大限度强化学习,并引入谈话一致性奖励,直至模子在推理任务上达到拘谨;面向推理的强化学习拘谨后,期骗生成的查验点收罗新的SFT数据,从而融入来自其他范畴的数据,以增强模子在写稿、脚色演出和其他通用任务中的能力;终末,为了进一步使模子与东说念主类偏好保持一致,实施次级RL阶段,旨在提高模子的有用性和无害性、精好意思其推理能力。通过冷启动和多阶段测验,R1模子最终具备较强的推感性能,同期在可读性上阐扬较好。
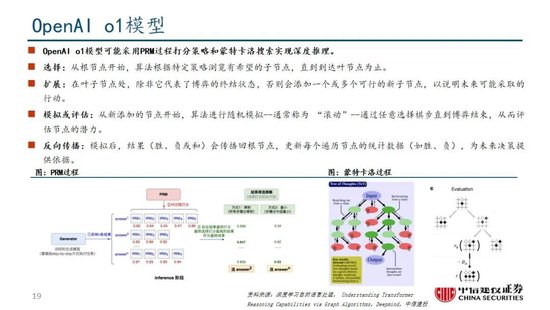
R1系列模子提供了RL Scaling Law的可行所在。现实上,在OpenAI推出o1模子时即发现了推感性能跟着测验时辰和测试时辰筹算而平定进步的“RL Scaling law”,但业内尚未通过过程奖励模子(PRM)和蒙特卡洛树搜索(MCTS)等方法作念出较好的效果,R1的时间证明更是提到PRM和MCTS存在难以限度化拓展、奖励糊弄等问题。R1模子的时间证明提供了一种多阶段测验的时势,其中在第一阶段RL过程中,研究东说念主员不错通过扩大RL测验集的时势进步模子性能,或为一种不错考证的“RL Scaling law”所在;OpenAI首席研究官Mark Chen也承认,“DeepSeek简直寂然发现了一些o1的中枢念念路”。
蒸馏使小模子具备较强逻辑推理能力的念念路或与OpenAI o1-mini不同。据张俊林分析,o1系列模子更可能是重新测验的(OpenAI屡次强调o1-mini逻辑推理能力强,但活着界学问方面弱;要是其基于GPT系列模子而来,天下学问应该不会弱于GPT 4o-mini),而DeepSeek-R1则是在V3的基础上通过强化学习测验得到。因此,DeepSeek通过向更高效的小模子蒸馏DeepSeek-R1的输出,权贵进步小模子推理能力,更可能走出了与OpenAI o1-mini不同的说念路,从而现实上冲破了之前“小模子逻辑推理能力难以通过蒸馏进步”的研究论断。
此时,小模子有望通过“能力分治”(DCA)的模式将谈话、天下学问及逻辑推理三个能力解耦,即谈话能力靠小模子自身、逻辑推理靠RL+蒸馏,天下学问靠外挂RAG,从而具备当今最强壮模子的能力,关于中袖珍开发者而言,部署模子也将愈加友好。
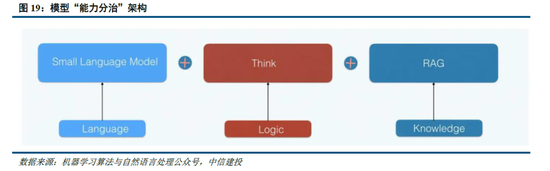
咱们觉得,DeepSeek-V3/R1系列模子的中枢突破在于1)时间及架构升级权贵优化模子测验成本,即工程优化了MoE模子架构,瞻望畴昔各厂商仍将围绕MoE模子进行防卫力头的架构优化;2)组相对策略优化算法(GRPO)实质上仅依赖模子自身近些迭代,罢了了“反念念能力”;3)提供了一种具体可行的“RL Scaling law”所在,各厂商或将跟进并连接探索其他所在;4)蒸馏使小模子具备较强逻辑推理能力,有望促进中袖珍开发者推出关联应用。
2.2 第五问:Janus系列模子时间调动有哪些?
Janus系列模子缓解多模态清楚和生成的冲突,进步模子能力阐扬。多模态清楚与生成任务自己存在视觉编码器需求的冲突,其中在理罢免务中,视觉编码器的目的是索求高头绪的语义信息并进行示意;而生成任务则主要柔和生成局部细节并在图像中保持全局一致性,因此需要低维度编码示意空间结构和纹理细节。Janus系列模子的中枢时间在于罢了多模态清楚与生成的解耦,通过2 个寂然的视觉编码旅途,缓解多模态清楚和生成的冲突,从而提高模子的能力阐扬和可扩展性。
多模态生成模子架构尚无定论,自记忆和扩散模子持续发展。当今图像生成模子主要包括以Transformer 为代表的自记忆生成、以 DDPM、LDM、DiT 为代表的扩散模子,以及 MaskGIT、MAR等掩码自记忆图像生成三类架构。自记忆架构通过算法逐个生成像素,DeepSeek的Janus系列模子为其中代表;掩码自记忆则优化了单次像素生成数目和缓序,提高了自记忆模子的速率和阐扬;扩散模子的代表包括Sora,其将图像生成示意成噪声图像变化至主义图像的过程,输入输出彻里彻外都是完竣图像。当今,自记忆和扩散模子均有前沿时间持续性突破,带来模子能力的持续进步。
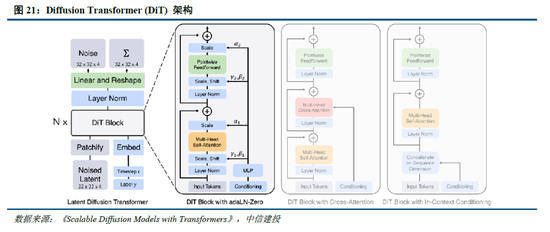
咱们觉得,多模态模子合座仍处于时间探索过程中,Janus系列中枢在于提供了一种清楚和生成解耦的架构,一定程度进步了模子阐扬,后续自记忆和DiT时间将进一步发展,带来多模态模子性能的持续优化。
2.3 第六问:DeepSeek数据集的特色是什么?
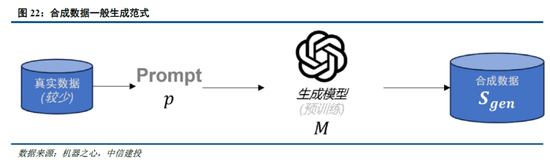
合成(生成)数据在大模子测验过程中阐扬着要紧作用。在高质地测验数据耗尽,以及互联网中充斥普遍噪声数据的配景下,合成数据已成为大模子测验过程中数据集的要紧起原, 截止 2024 年 9 月,在 Hugging Face 平台上标注为 “合成” 的数据集已突出 1000 个。具体而言,合成数据主要由算法、模子生成,为大模子测验提供更丰富且针对性强的信息,匡助拓展模子性能:
通用大模子:在通用大模子测验中,合成数据主要用于丰富数据集,进步模子性能。以 DeepSeek-V3 的测验为例,其在监督微调阶段借助 DeepSeek-R1 模子生成样本数据,经 RL 测验后用隔绝采样筛选高质地数据用于最终模子测验,灵验进步了模子的推理能力。
推理模子:在推理模子测验中,合成数据主要用于优化测验经由。举例,DeepSeek-R1在冷启动阶段期骗R1-Zero生成+东说念主工标注数据进行微调,并在监督微调阶段通过V3模子收罗了约60万条与推理关联的测验样本,以及约20万条与推理无关的测验样本。此外,R1向小模子蒸馏的过程现实上亦然通过R1生成数据对小模子进行监督微调罢了的。
多模态模子:多模态模子测验中,合成数据能改善数据质地,权贵强化视觉生成能力。Janus - Pro 在预测验阶段相较于 Janus 引入约 7200 万个合成好意思学数据样本,使真实数据与合成数据比例达到 1:1,从而加快了模子拘谨速率,进步图像生成质地。而Kimi-1.5手脚以强化学习时势测验的多模态大模子,分别在预测验阶段通过合成数据强化了推理和基于学问任务的解答能力,在多模态测验阶段合成了图像文本交错数据。
GRPO 算法在一定程度上使模子解脱东说念主类造就的不断。如 2.1 所述,R1 - Zero 模子在 RL 过程中延续了 DeepSeek - V3 组的相对策略优化算法(GRPO)。该算法通过组内奖励对比优化策略,无需额外的判别器,最终罢了了测验集上平均响应长度的持续进步,使模子自然地学主见过更多念念考时辰来科罚推理任务。现实上,GRPO 关于 RL 数据集的处理相同具有要紧意念念。具体而言,PPO 算法需要依赖价值模子推断状态价值,以匡助筹算上风函数;而 GRPO 算法只对输出的谈话内容进行相对上风筹算,不需要遐想价值模子。价值模子的设定自己就包含了东说念主类偏好,这种偏好通过东说念主类造就限制了数据集的价值。而 GRPO 算法本色上可看作模子生成内容的自我博弈,它能让模子解脱东说念主类造就的不断,通过进步念念考深度不时拓展性能,最终以至可能超越东说念主类水平。
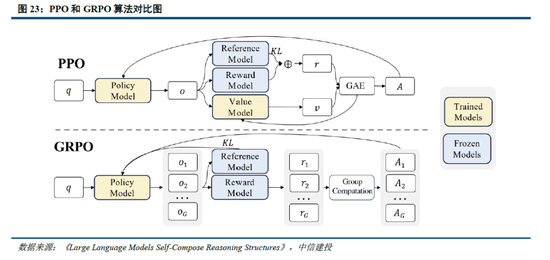
咱们觉得,DeepSeek-V3/R1/Janus等模子关于合成数据的应用合乎大模子研究趋势,而GRPO 算司法进一步使模子在RL过程中解脱了东说念主类造就的限制,从而粗鲁最大程度挖掘数据集的价值,向模子超越东说念主类,最终罢了AGI的说念路进发。
2.3 第七问:Scaling Law到底是否灵验?
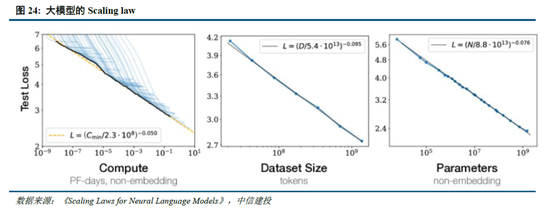
测验侧Scaling law推动模子能力持续进步,但仍面对时间、算力、数据的制约。早在2020年,OpenAI即在论文中建议了“Scaling law”,其内涵在于大模子的最终性能主要与筹算量、模子参数目和测验数据量三者的大小关联,而与模子的具体结构(层数/深度/宽度)基本无关。在“Scaling law”的念念路下,业内追求在测验侧用更多的高质地数据,测验更大参数限度的模子,尤其在MoE架构并行筹算的加持下,大模子参数以至粗鲁进步至万亿以上,极大程度提高了模子的效果。
关联词,受到时间、算力、数据的制约,测验侧“Scaling law”正面对瓶颈:1)更高参数限度的模子测验比较复杂:当参数限度进步到万亿限度,模子进一法度整的时间时势仍待突破;2)算力限度一定程度制约了模子发展:英伟达 H100当今不错作念到单一集群 3.2 万张卡充分互联,每2小时会出错一次(Founder Park访谈拾象科技 CEO 李广密)。一朝算力集群增多到10万卡,可能每20-30分钟即会出错一次,对数据中心的运维能力条目较高,不然会导致算力期骗率昭彰着落。此时需要性能更强的算力卡出现。3)高质地数据缺失:早有音尘称大模子测验已经耗尽了高质地数据,因此要是仅仅浅薄进步测验集限度,时常重复的数据占据了主要部分,从而对模子能力的进步有限。而数据合成的时间仍未能突破,相同一定程度上制约了模子的发展。
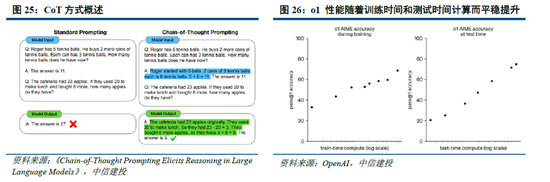
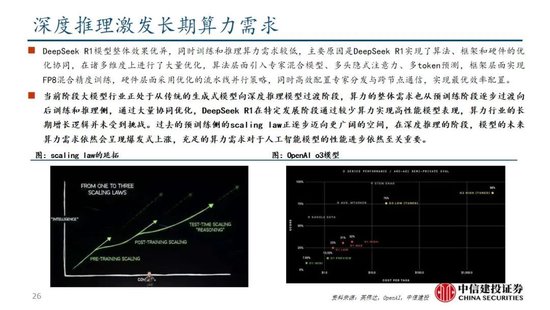
念念维链等时势打开推理侧大模子能力进步空间。当测验侧“Scaling law”程度相对放缓,OpenAI于2024年9月发布了系列新模子o1,其期骗强化学习时间,通过提高推理侧的念念考时辰,大幅优化了模子阐扬;还粗鲁在测验过程中生成高质地数据,科罚自然数据缺失的问题。以念念维链时间为例,其类比东说念主类念念考过程,使大模子在推理过程中把复杂问题拆解成若干浅薄门径,从用户建议的问题启程,逐渐生成正确谜底。OpenAI o1模子性能跟着测验时辰和测试时辰筹算而平定进步,后测验及推理阶段念念考深度(时辰)或将成为 新的“Scaling law”;相较于OpenAI未开源推理算法,DeepSeek-R1系列模子提供了RL Scaling Law的可行所在,有望促进各厂商跟进并连接探索其他推理侧拓展所在。
Scaling law三条旅途皆头并进,助力模子性能持续进步。正如英伟达CEO黄仁勋在CES 2025上的主题发言提到的,o1模子推出后,大模子Scaling law已经现实上分为了三个旅途:
Pre-Training Scaling:对应OpenAI 2020年建议的论断,测验数据限度越大、模子限度越大、筹算资源插足越多,AI模子的性能就会相应进步。尽管Pre-Training Scaling当今受时间、算力、数据影响遭受瓶颈,但更强壮的基础模子仍然是各厂商追求的主要所在,DeepSeek-R1的时间证明相同建议,“更大基础模子发现的推理模式关于进步推理能力至关要紧”。畴昔跟着MoE架构、模子Infra等方面的优化,Pre-Training Scaling有望持续发展。
Post-Training Scaling:包括强化学习和东说念主类反馈等时间,通过输入普遍优质的教导,优化模子性能阐扬。现实上,受限于东说念主类责任遵循,原有的东说念主类反馈强化学习(RLHF)存在难以限度化扩展的问题(举例东说念主工标注数据遵循较低、不同标注者圭臬不一致等),而DeepSeek-R1纯RL的时间决策现实上冲破了这种限制,为各厂商提供了Post-Training Scaling的可行决策。
Test-Time Scaling:强调重新调配资源,即在推理阶段辩论插足若干算力,并期骗念念维链将问题理会成若干个小门径一一科罚。通过在模子推理阶段愈加深刻的念念考,模子将具备更强壮的性能。

咱们觉得,Scaling Law仍灵验,同期RL时间的不时迭代为模子能力的限度化扩展带来了新的所在。稀奇是DeepSeek通过架构和时间创新,建议了纯RL和分阶段的模子测验方法,并罢了了较好的性能阐扬。瞻望各厂商将陆续跟进DeepSeek的算法所在,并不时对架构进行调换,以探索出更为想象的模子优化时势。
三、DeepSeek-R1促进AI平权,产业链享受发展红利
3.1 第八问:R1是否意味着AI平权已经罢了?
DeepSeek-R1开源激勉全球复现飞腾,小模子+RL罢了“反念念”涌现。在好意思国对中国实施 AI 芯片禁闭的配景下,DeepSeek以极低的成本奏凯测验出踏进全球第一梯队的推理模子 R1。同期,DeepSeek 完全开源了模子权重,所遵命的 MIT License 开源合同极为宽松,允许其他开发者将模子用于生意用途并进行模子蒸馏,被Facebook首席东说念主工智能科学家杨立昆誉为“开源模子对闭源模子的奏凯”。
R1发布以来,全球前沿团队积极复现,当今已取得较好见效。其中,UC伯克利的团队在CountDown游戏中复现了DeepSeek R1-Zero,以不到30好意思金的成本通过强化学习,使3B的基础谈话模子完成自我考证和搜索;港科大的团队只用了8K个样本,就在7B模子上复刻出了DeepSeek-R1-Zero和DeepSeek-R1的测验,使模子在复杂的数学推理上取得强壮的收尾;以至全球最洞开源平台HuggingFace团队,也在1月26日官宣脱手复刻DeepSeek-R1的通盘pipeline,并将在复刻完成后,开源通盘的测验数据和剧本。
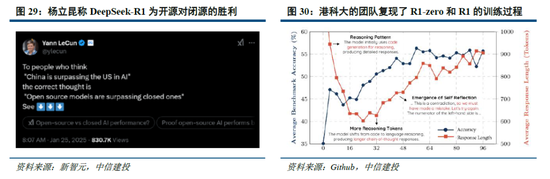
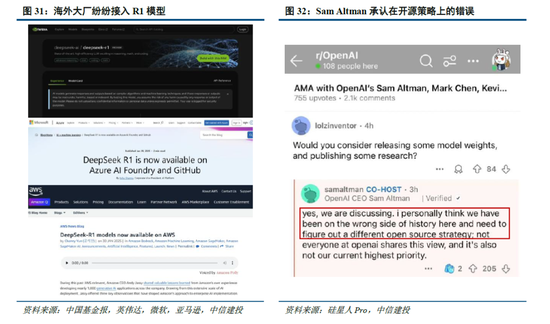
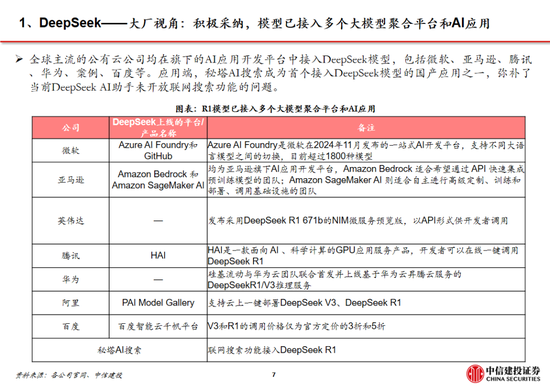
全球大厂接贯穿入R1,DeepSeek冲击下OpenAI政策所在或将转向。尽管好意思国质疑DeepSeek在安全性、阴私方面的问题,但英伟达、英特尔、亚马逊、微软、AMD等国外巨头仍纷繁在自家居品中接入了DeepSeek;国内硅基流动和华为云相同贯串首发并上线了基于华为云昇腾云干事的DeepSeek R1/V3推理干事。受DeepSeek全球热度冲击,Sam Altman承认在开源策略上“站在了历史失实的一边”,并示意正在连接开源部分模子。此外,OpenAI于2月1日迫切更新了o3-mini系列,即使是免用度户也不错通过选拔“Search+Reason”来使用体验o3-mini的搜索功能。关联词,o3-mini模子面前的订价为每百万输入 tokens 0.55好意思元(缓存射中)/ 1.1好意思元(缓存未射中),每百万输出 tokens 4.4好意思元,远高于R1模子。
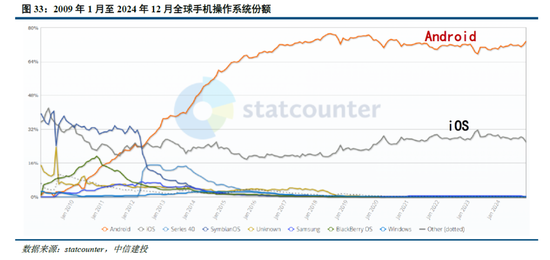
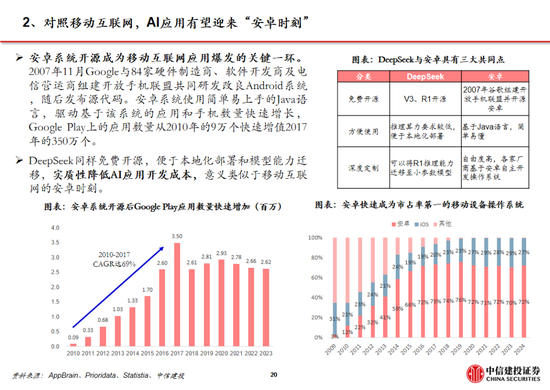
参考安卓及iOS份额变化,开源生态有望为AI产业注入活力。在智高东说念主机操作系统范畴,安卓的开源与 iOS的封闭带来了迥然相异的生态模式:
安卓:Android公司成立于2003年,2005年被Google收购,并在2007年庄重推出了Android操作系统。生态上,安卓系统开源开放,允许繁多手机厂商基于其底层架构进行定制化开发,使其市集份额从2008年的2.8%进步到2011年的48%,但同期也带来了专利诉讼、软件盗版和系统安全等一系列问题;2011年,Google 推出 Android 4,从此安卓开拓逐渐正规化、圭臬化,直至2024年12月,安卓操作系统市集份额已经达到73.49%。
iOS:相同在安卓系统庄重发布的2007年,苹果发布了搭载iOS系统的第一代iPhone,开启了智高东说念主机的新时期。相较于安卓的开放,苹果iOS系统采取封闭式生态,严格把控软件审核过错,一定程度限制了系统的纯真性,但为用户提供了一致且高质地的使用体验。从市集份额看,频年来iOS系统的市占率相对雄厚,2024年12月市集份额为26.04%,低于2009年1月iOS的市集份额35.56%。
AI产业:类比手机操作系统范畴,面前AI 产业相同面对开源和闭源之争。参考安卓系统发展历程,开源模式粗鲁引诱全球范围的开发者参与AI时间创新,自后者粗鲁基于已灵验果快速进行应用开发与居品迭代,从而推动 AI 应用的快速落地,推动AI产业加快发展。
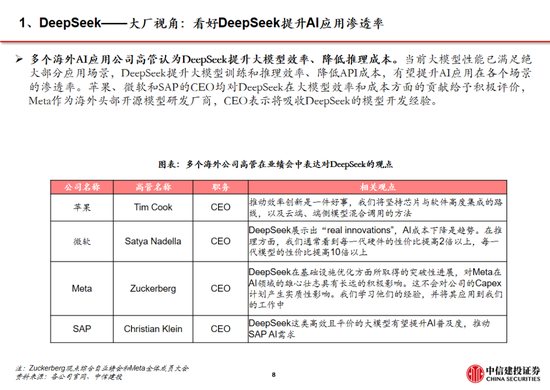
咱们觉得,DeepSeek-R1手脚开源模子性能接近头部闭源模子o1,一定程度上已经反应了AI平权。现实上,往日OpenAI的率先更多基于先发上风,而当开源模子的性能罢了对闭源模子的追逐,全球的团队的研发能力粗鲁使开源模子的性能恒久位于前哨。近期各研究团队对R1模子的积极复现更是侧面考证了开源模式的上风。此外,DeepSeek-R1使小模子具备推理能力成为可能,更低的成本将更成心于开发者探索AI的现实落地,带来更有价值的居品。
3.2 第九问:DeepSeek出圈对产业的影响有几何?
DeepSeek以其低成本、高性能全面影响AI产业链。AI产业链约莫可分为基础层(算力、数据、时间等)、模子层(通用/行业大模子、开发平台)和应用层(通用/垂域应用、Agent等)。尽管首创东说念主梁文锋称DeepSeek时间突破仅仅“好意思国每天发生的普遍创新里相配普通的一个”,但其低成本、高性能,以及为小模子带来强壮推理能力的蒸馏时势,仍对AI产业链产生了冲击:
算力:DeepSeek的爆火使得“杰文斯悖论”这照旧济学名词受到柔和,它是指“燃料遵循的提高时常会增多燃料使用”。要是将该表面拓展到算力范畴,模子对算力应用遵循的进步反而会带来算力需求的增长。现实上,“杰文斯悖论”反应了浅薄的经济学旨趣——当需求价钱弹性所有大于1,价钱着落则会带来销售收入增多。因此,DeepSeek影响下算力需求是否增多的过错在于算力的价钱弹性,而这又受到算力用途的影响(一般来说,商品用途多,需求弹性就越大)。
算力手脚新一轮科技翻新的底层基础,将会应用于千行百业,DeepSeek-R1使小模子能通过蒸馏具备较强逻辑推理能力,更进一步加快了下流应用的产生,则算力的价钱弹性更可能大于1,合乎“杰文斯悖论”,从而持续保持欢叫的需求。此外,梁文锋在访谈中提到高端芯片禁运或将成为卡点,相同反应了算力芯片自主可控的要紧性。
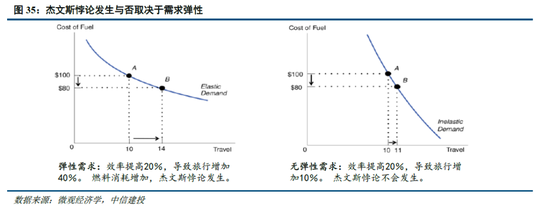
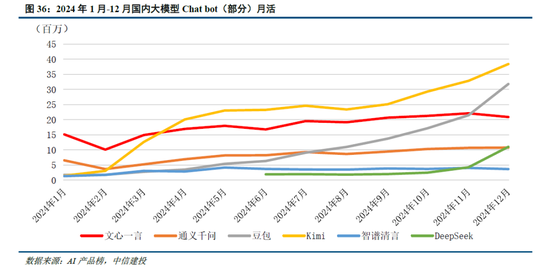
模子:DeepSeek-R1模子的突破现实上反应了中好意思在前沿大模子差距的收缩。以发布于2024年3月的GPT-4为例,2024年1月发布的智谱GLM-4才在部分benchmark上达到了其90%-100%的水平,模子差距在10个月以上;而2025年1月发布的R1已经接近OpenAI 2024年9月发布的o1模子,模子差距裁汰到4个月掌握。而大模子自己过火对应的Chat bot居品,用户切换成本低,存在“赢者通吃”的痛快,举例kimi 在2024年3月罢了高下文无损输入长度进步至200万字,爆火出圈带来流量的大幅飞腾;2024年12月字节火山引擎热度攀升,以及DeepSeek-V3的发布相同带来了流量的快速进步。在此配景下,瞻望大厂将跟进DeepSeek模子层的研发,时间开源亦将促进大厂持续插足,形成正反馈。此外,DeepSeek通过纯RL算法、架构优化等时势罢了了模子性能的进步,或将促进各厂商在关联范畴进行更多的探索。
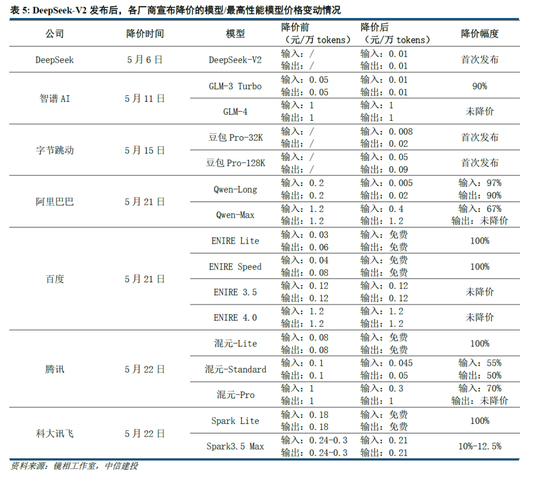
应用:DeepSeek-V3/R1手脚通用/推理方面的基础模子,性能升级及在种种 Benchmark 跑分中的提高,自己就为应用落地带来了更大的可能性。关联词,关于开发者而言,更过错的点在于模子粗鲁和应用适配调优,提供雄厚性的API干事,以及性价比更高的tokens成本。参考2024年5月DeepSeek-V2发布后带来的大模子价钱战,即使模子成本更高,字节、阿里等大厂亦按照烧钱补贴的逻辑大幅降价,本色上是因为开发者价钱敏锐,大厂痛快亏钱霸占市集份额,栽培开发者使用风俗。
辩论到DeepSeek-R1开发和调用成本自己较低,还通过蒸馏的时势带来了小模子推理能力的进步,则应用开发者粗鲁以更低的成本部署模子或调用API,并保持相对优秀的性能。当应用开发门槛阻挡,瞻望会出现更多居品探索所在,直至出现具有突破性的 “killer”应用。同期,DeepSeek-R1的廉价,相同有望带来推理模子新一轮的价钱战(o3-mini的价钱自己已造就证了这一不雅点),为开发者带来更多性价比之选。终末,当DeepSeek模子的能力达到全球第一梯队后,其手脚国内厂商能为国内应用开发者提供更雄厚的干事(调用GPT API可能会受到多样限制),亦将促进种种应用产生。
数据:DeepSeek 系列模子的测验过程仍突显了高质地数据的要紧性。举例V3模子测验时使用了14.8 万亿涵盖多种范畴媾和话的token;R1通过全心筛选和处理的冷启动数据进步了模子性能和可读性;Janus-Pro 在测验时相同较前代模子增多约 9000 万用于多模态清楚的样本和约 7200 万用于视觉生成的合成好意思学数据。结合RL范式的可能性,瞻望高质地数据仍将在模子测验中具有要紧意念念。
四、投资建议
4.1 第十问:DeepSeek将带来哪些投资契机?
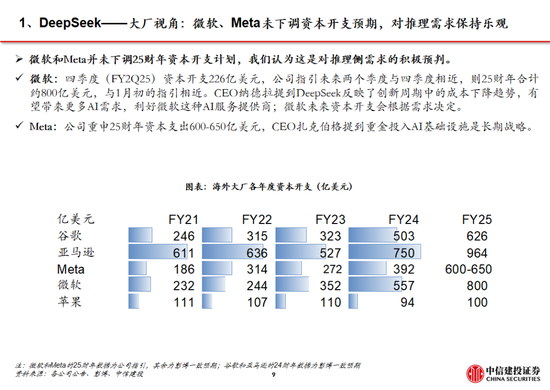
算力:算力手脚新一轮科技翻新的底层基础,将持续受益于千行百业的应用需求。叠加 DeepSeek - R1 为推理范式带来泛化的可能性,瞻望各厂商时间探索下算力产业链持续高景气。此外,中好意思AI竞争加重,高端算力芯片禁售下自主可控要紧性进一步突显。建议柔和以国产算力和AI推理需求为中枢的算力过错,尤其是IDC、干事器、国产芯片等算力配套产业。
应用:DeepSeek-R1有望激勉新一轮大模子API降价,小模子通过蒸馏具备强壮推理能力,这也将促使开发者探索更多应用落地的可能性。AI应用手脚新一代坐褥力器具,看多C端软件的持续发展,B端应用软件生意化进展更快。建议柔和B端Agent,其中OA+ERP手脚中枢进口,AI结合更易,有望率先生意化,其次柔和用户量多、生态好且可云化的软件公司等。
端侧:小模子能力进步相同促进了端侧模子部署,咱们看好AI结尾手脚新一代筹算平台爆发可能。伊始,咱们觉得AI+熟谙手脚高频应用场景有望率先落地,稀奇熟谙部东说念主工智能赋能熟谙活动陆续鼓励,有望带动AI学习机、AI熟谙大屏等需求增多,推选视源股份、科大讯飞等;其次,咱们觉得AI眼镜、AIPC、机器东说念主等新结尾的出货量有望跟着模子升级后使用范围的增多而增多,因此建议柔和以AI眼镜、PC、机器东说念主为代表的结尾供应商或里面中枢软件供应商。
数据 :高质地数据仍然是大模子测验中不行或缺的一环,B端 Agent落地亦需要行业know-how进行微调。建议柔和向量数据库关联公司、数据处理类企业,以及具备行业侧专科数据的厂商。
风险教导:(1)AI产业生意化落地不足预期:当今各过错AI 居品的生意化模式尚处于探索阶段,要是各过错居品的鼓励节律不足预期,或对关联企业功绩形成不利影响;(2)市集竞争风险:国外 AI 厂商凭借先发上风,以及较强的时间聚集,在竞争中处于上风地位,要是国内 AI 厂商时间迭代不足预期,筹画情状或将受到影响;同期,当今国内已有繁多企业插足AI居品研发,后续可能存在同质化竞争风险,进而影响关联企业的收入;(3)政策风险:AI时间的发展径直受列国政策和监管影响。跟着AI在各个范畴的渗入,政府可能会进一步出台相应的监管政策以标准其发展。要是企业未能实时适合和投降关联政策,可能面对相应处罚,以至被动调换业务策略。此外,政策的不笃定性也可能导致企业政策筹算和投资决策的失实,增多运营的不笃定性;(4)地缘政事风险:在全球地缘政事环境的波动下,尤其好意思国对中国的出口限制或将径直影响国内企业算力芯片的获取,进而影响其居品研发和市集竞争力。同期,地缘政事风险也可能导致 AI 居品开拓国外市景观临迂回,影响关联企业的营收情况。
证明起原

证券研究证明称呼:《DeepSeek中枢十问十答》
对外发布时辰:2025年2月4日
证明发布机构:中信建投证券股份有限公司
本证明分析师:
应瑛 SAC 编号:S1440521100010
02 DeepSeek R1深度解析及算力影响几何
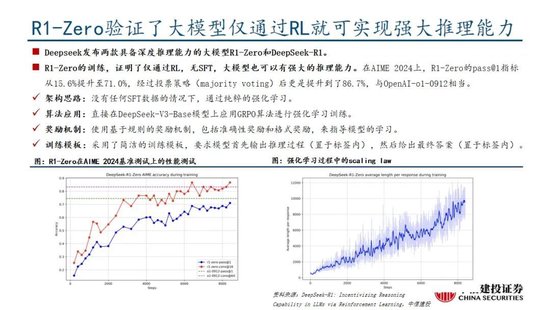
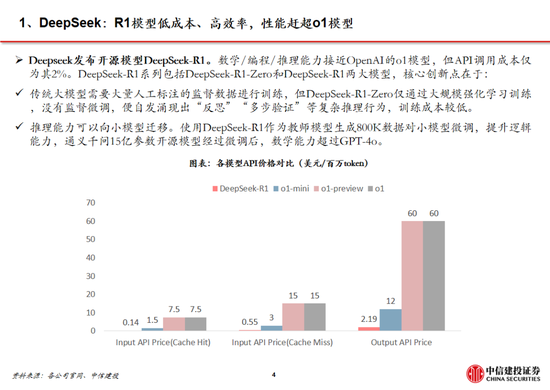
Deepseek发布深度推理能力模子,性能和成本方面阐扬出色。Deepseek发布两款具备深度推理能力的大模子R1-Zero和DeepSeek-R1。R1-Zero采取贞洁的强化学习测验,模子效果靠拢OpenAI o1模子,诠释了大谈话模子仅通过RL,无SFT,大模子也不错有强壮的推理能力。然则R1-Zero也存在可读性差媾和话羼杂的问题,在进一步的优化过程中,DeepSeek-V3-Base阅历两次微调治两次强化学习得到R1模子,主要包括冷启动阶段、面向推理的强化学习、隔绝采样与监督微调、面向全场景的强化学习四个阶段,R1在推理任务上阐扬出色,稀奇是在AIME 2024、MATH-500和Codeforces等任务上,取得了与OpenAI-o1-1217相比好意思以至超越的收成。
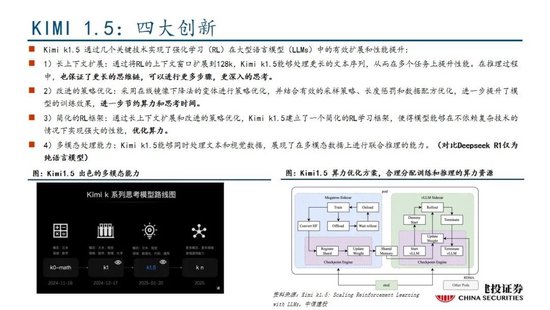
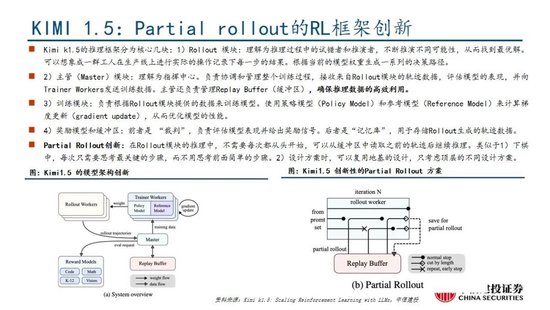
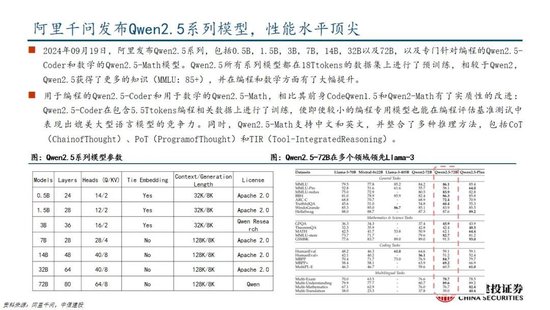
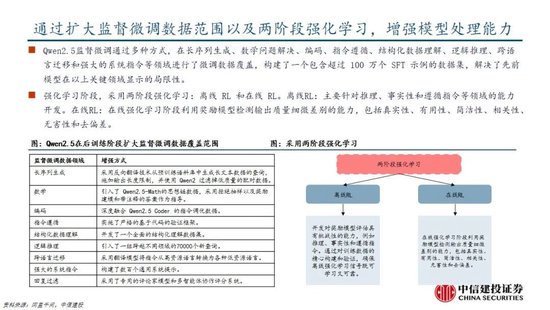
国产模子迈向深度推理,策略创新百花皆放。在Deepseek R1-Zero模子中,采取的强化学习策略是GRPO策略,取消价值麇集,采取分组相对奖励,特意优化数学推理任务,减少筹算资源消耗;KIMI 1.5采取Partial rollout的强化学习策略,同期采取模子合并、最短隔绝采样、DPO 和long2short RL策略罢了短链推理;Qwen2.5扩大监督微调数据范围以及两阶段强化学习,增强模子处理能力。
DeepSeek R1通过较少算力罢了高性能模子阐扬,主要原因是DeepSeek R1罢了算法、框架和硬件的优化协同。DeepSeek R1在诸多维度上进行了普遍优化,算法层面引入内行羼杂模子、多头隐式防卫力、多token预测,框架层面罢了FP8羼杂精度测验,硬件层面采取优化的活水线并行策略,同期高效配置内行分发与跨节点通讯,罢了最优遵循配置。面前阶段大模子行业正处于从传统的生成式模子向深度推理模子过渡阶段,算力的合座需求也从预测验阶段逐渐过渡向后测验和推理侧,通过普遍协同优化,DeepSeek R1在特定发展阶段通过较少算力罢了高性能模子阐扬,算力行业的耐久增长逻辑并未受到挑战。往日的预测验侧的scaling law正逐渐迈向更浩繁的空间,在深度推理的阶段,模子的畴昔算力需求依然会呈现爆发式飞腾,填塞的算力需求关于东说念主工智能模子的性能进步依然至关要紧。












风险教导:
大模子时间发展不足预期:大模子属于先进AI算法,若后续大模子算法更新迭代效果不足预期,则会影响大模子演进及拓展,进而会影响其生意化落地等;
生意化落地不足预期:大模子的生意落地模式在业界中普遍处于探索阶段,用户关于大模子的接受程度和生意化变现能力可能不足预期;
算力基础设施因循不足预期:好意思国制裁中国高技术企业,对中国形成芯片、算力的禁闭,大谈话模子测验过程中需要普遍算力资源,需要柔和中好意思联系带来的算力的压力;
政策监管力度不足预期:大谈话模子带来新的麇集生态生意,尚属于前期成长阶段,政策监管难度加大,关联法律法例尚不完善,政策监管力度可能不足预期;
数据数目与数据质地不足预期:大型谈话模子需要普遍的高质地数据进行测验,若数据数目和质地存在短板,则会影响大谈话模子效果。
证明起原
证券研究证明称呼:《DeepSeek R1深度解析及算力影响几何》
对外发布时辰:2025年2月3日
证明发布机构:中信建投证券股份有限公司
本证明分析师:
于芳博 SAC 编号:S1440522030001
庞佳军 SAC 编号:S1440524110001
辛侠平 SAC编号:S1440524070006
研究助理:孟龙飞
03 重心推选端侧AI产业
DeepSeek在保持模子优异性能方针的同期大幅阻挡测验和推理成本。2025年1月20日,DeepSeek-R1发布,以 DeepSeek-V3 模子为基础,通过结合大限度强化学习、内行模子架构、FP8羼杂精度等时间技能阻挡测验成本,同期具备深度念念考能力,在数学、代码、自然谈话推理等多个任务上性能并排 OpenAI O-1217 模子。DeepSeek-R1发布后,在保持较为优异的性能方针基础上,市集关于其在测验和推理端的低成本尤为爱好。DeepSeek-V3 使用 2048 块 H800 GPU 完成了 6710 亿参数的测验,测验成本为 557.6 万好意思元,DeepSeek-R1模子的每百万输出 tokens 为 16 元,均权贵低于同等水平的模子成本。
期骗DeepSeek模子生成的数据样本罢了小参数目的模子蒸馏,进步模子性能。DeepSeek R1 生成 80 万条高质地推理数据样本,使用这些推理数据对较小的基础模子进行监督微调(SFT),将 DeepSeek R1的学问和推理能力进行移动。DeepSeek 团队开源了多个基于不同限度的 Qwen 和 Llama 架构的蒸馏模子,如 DeepSeek - R1 - Distill - Qwen - 1.5B、DeepSeek - R1 - Distill - Llama - 8B、DeepSeek - R1 - Distill - Llama - 70B 等。
高性能、轻量化、低成本的模子能力将权贵推动端侧AI产业发展。端侧硬件开拓是将大模子能力进行实归天输出落地的过错过错,近日OpenAI 的 CEO Sam Altman 在接受媒体采访时也闪现 OpenAI 将开发可替代手机的生成式 AI 专用结尾。国内物联网模组厂商在端侧AI范畴具备先发上风,并积极进行产业布局,如好意思格智能正加快开发DeepSeek-R1模子在端侧落地应用及端云结合合座决策,2025年将推出单颗模组算力达到100Tops的高阶AI硬件,远期筹算AI模组算力突出200Tops。
风险教导:国际环境变化对供应链的安全和雄厚产生影响,对关联公司向国外拓展的程度产生影响;东说念主工智能行业发展不足预期,影响云筹算产业链关联公司的需求;市集竞争加重,导致毛利率快速下滑;汇率波动影响外向型企业的汇兑收益与毛利率,包括ICT开拓、光模块/光器件板块的企业;数字经济和数字中国设立发展不足预期;电信运营商的云筹算业务发展不足预期;运营商本钱开支不足预期;云厂商本钱开支不足预期;通讯模组、智能限定器行业需求不足预期。
证明起原
证券研究证明称呼:《重心推选端侧AI产业》
对外发布时辰:2025年2月5日
证明发布机构:中信建投证券股份有限公司
本证明分析师:
阎贵成 SAC 编号:S1440518040002
SFC 编号:BNS315
刘永旭 SAC 编号:S1440520070014
SFC 编号:BVF090
武超则 SAC 编号:S1440513090003
SFC 编号:BEM208
研究助理:朱源哲
04 DeepSeek激活创新竞争,AI应用迎来“安卓时刻”
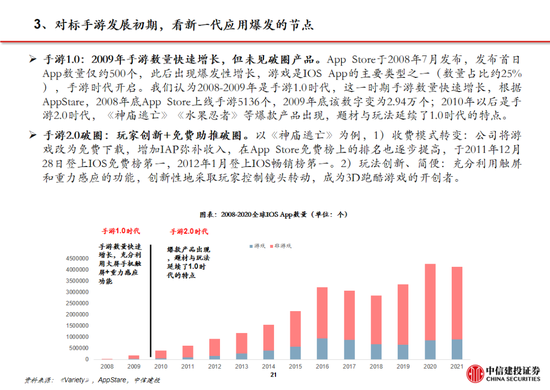
应用开发迎来“安卓时刻”
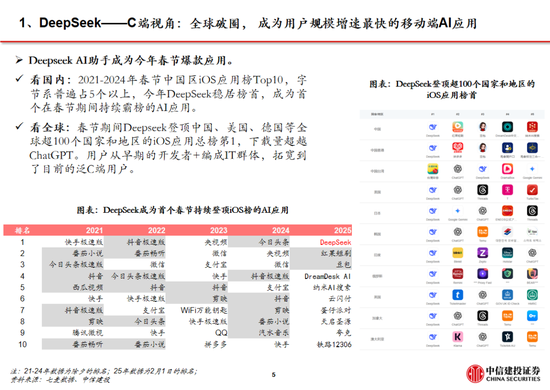
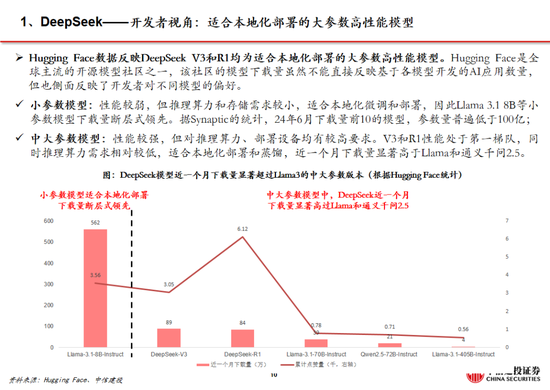
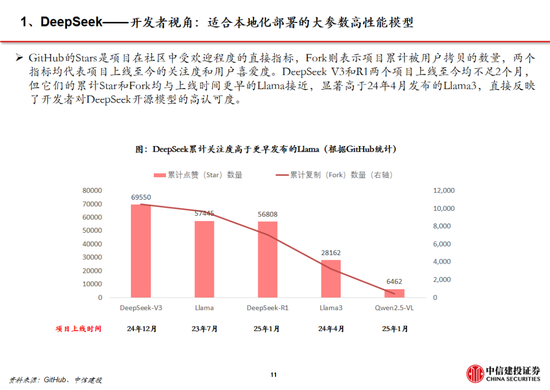
追忆安卓与iOS应用的发展,咱们率先建议不应只柔和大模子自己的用户数及活跃度,更应该柔和开发者,尤其是中小开发者的数目。据GitHub,在Llama比DeepSeek开源时辰早1年半的情况下,当今DeepSeek R1在GitHub上的开发者点赞数目已经达到约5.7万,接近Llama。证据GitHub、Hugging Face社区上的开发者实测,经过R1微调的80亿参数小模子不错在个东说念主札记本中运行,土产货化部署门槛权贵着落,应用的开发将迎来百花皆放。
有用户有居品能力的公司,仍将“赢在起跑线”
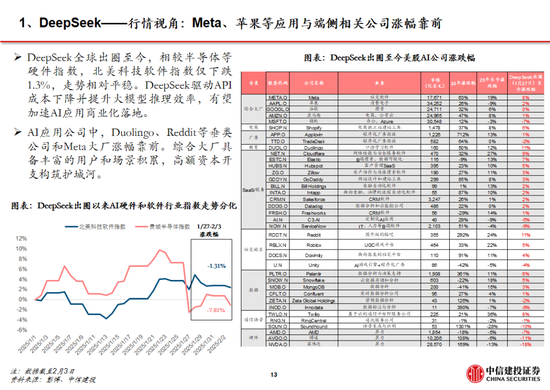
自然春节期间Deepseek的柔和度赶超字节豆包,但咱们觉得以字节越过为代表的中国头部互联网公司,手捏高粘性+大DAU居品,叠加强居品能力。在第二阶段的应用、场景等范畴,用户数+居品力+生意变现能力,仍然将匡助他们在接下来的竞争中霸占先机。
当今豆包全球累计下载量(约9000万)仍然昭彰高于Deepseek(约2000万),而其他领有用户基础和居品能力的公司,也有契机奋发有为。







风险教导:宏不雅经济风险,版权保护力度不足预期,学问产权未辞别明确的风险,与IP或明星迎阿中断的风险,全球审好意思取向发生调动的风险,竞争加重的风险,用户付费意愿低的风险,消费风俗难以改变的风险,关联公司公司料理风险,内容上线阐扬不足预期的风险,生成式AI时间发展不足预期的风险,居品研发难度大的风险,居品上线脱期的风险,营销买量成本上升风险,东说念主才流失的风险,东说念主力成本上升的风险,政策监管的风险,生意化能力不足预期的风险。
证明起原
证券研究证明称呼:《DeepSeek激活创新竞争,AI应用迎来“安卓时刻”》
对外发布时辰:2025年2月4日
证明发布机构:中信建投证券股份有限公司
本证明分析师:
杨艾莉 SAC 编号:S1440519060002
SFC 编号:BQI330
杨晓玮 SAC 编号:S1440523110001
05 DeepSeek土产货部署与全球资产配置组合追踪
Deepseek先容:DeepSeek,成立于2023年,是幻方量化的子公司,位于杭州的东说念主工智能公司。它于2024年末推出DeepSeek-V3模子(671B参数),性能超越多种开源模子,并接近顶尖闭源模子。2025年1月,DeepSeek发布R1系列模子(660B参数),在多项任务上阐扬优异,同期推出了几个小模子对标OpenAI的居品。DeepSeek通过其创新时间权贵提高了生成速率,并提供了具有竞争力的API干事订价。
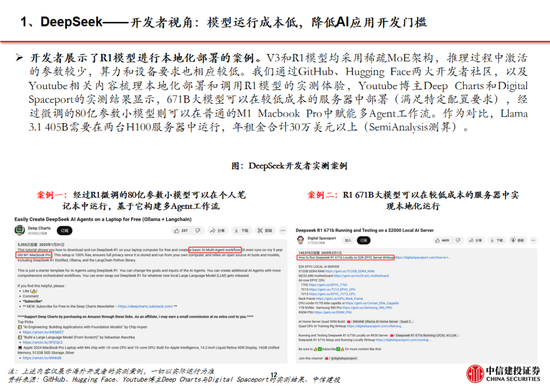
Deepseek土产货部署方法:Ollama是一个开源器具,用于在个东说念主开拓上高效运行大型谈话模子(LLMs),无需依赖云表。DeepSeek-R1模子可通过Ollama罢了土产货部署:伊始,从Ollama官网下载恰当系统的Windows版块并装配,完成后系统托盘会出现Ollama图标。其次,访谒“Models”页面选拔DeepSeek-R1,并证据显卡配置(如4090显卡24G显存)选拔32B版块,复制对应的运行指示。然后,在敕令行窗口中实行该指示以下载和运行模子(32B版块约19GB)。为进步用户体验,可采取Docker+Open WebUI构建图文交互界面,以至将DeepSeek-R1 32B集成到微信中手脚智能体使用,享受其快速响应和深度念念考功能。
对AI范畴投资的念念考:通过DeepSeek官网与DeepSeek-V3对话,不错了解部署各版块模子对硬件的条目。普通札记本和台式机仅配备CPU,仅能拼集运行DeepSeek-R1-1.5B和7B,但响应速率慢,零落实用性。英伟达RTX 4090可较快运行DeepSeek-R1-32B,但在处理70B版块时阐扬欠安。中小模子如1.5B、7B和14B恰当浅薄的微信交流场景,但无法科罚复杂问题;32B模子具备深度念念考能力,适用于干事客户的微信交流。671B完竣版及70B模子需要企业级显卡如A100或H100因循,不恰当消费级硬件。云表部署虽可行,但存在数据阴私问题。DeepSeek-R1过火开源的袖珍化模子的高性能,推动中小企业和个东说念主开发智能助手,举例微信客服,这将权贵增多对算力的需求。
全球大类资产策略组合阐扬:全球多资产配置统统收益@低风险组合,今年薪金0.86%,比拟中债总钞票(总值)指数逾额收益0.40%。全球多资产配置统统收益@中高风险:今年薪金3.66%,相对万得FOF指数逾额收益3.61%。
风险教导:
DeepSeek的土产货部署算力条目来自DeepSeek-V3,AI搜索和分析论断可能会受到麇集贵寓的影响。
大类资产配置自然粗鲁灵验分布风险,但在某些市集环境下或策略遐想中也存在一些潜在的危急和局限性。以下是几项主要危急和局限性:
1. 高关联性导致风险分布效果阻挡:模子的中枢念念想是将投资组合的风险平平分派到各资产中,追求各资产风险孝敬换取。关联词,当某些资产之间的关联性较高时,协方差矩阵中的协方差项会较大,导致这些高关联性资产对组合的总风险孝敬增大。这么一来,投资组合的总风险将愈加依赖于这些高关联性资产,从而阻挡了风险平价模子的风险分布效果。
2. 市集环境变化可能导致模子失效:量化模子的灵验性基于历史数据的回测,但畴昔市集环境的变化可能与历史数据存在较大各异,导致模子失效。举例,市集的宏不雅环境、投资者的交游活动或局部博弈的变化,都可能影响因子的现实阐扬,进而使得风险平价或最大多元化策略无法罢了预期的效果。
3. 资产选拔的局限性:策略的效果在很大程度上取决于资产的选拔。资产的选拔和市集的波动性会对策略的阐扬产生要紧影响。
投资者需要证据市集环境和自身的风险偏好,纯真调换策略,并警惕模子失效的风险。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
牵累剪辑:何俊熹